Introduction
In the last article, we built a model based on the Poisson distribution using Python that could predict the results of football (soccer) matches. Whilst the model worked fairly well, it struggled predicting some of the lower score lines, such as 0-0, 1-0, 0-1.
In this article we'll look at how Dixon and Coles added in an adjustment factor to improve the model's performance.
All the code here builds on my last article so if you've not read that yet then I highly recommend going back and reading that one first.
Okay, let's get coding!
The Data
Just like last time, our model will work by predicting the number of goals scored / conceded by each team when they play each other based on their historical performances. Let's grab the same data as last time from football-data.co.uk.
import pandas as pd
df = pd.read_csv("https://www.football-data.co.uk/mmz4281/1718/E0.csv")
df[["Date", "HomeTeam", "AwayTeam", "FTHG", "FTAG"]].head()
| Date | HomeTeam | AwayTeam | FTHG | FTAG | |
|---|---|---|---|---|---|
| 0 | 11/08/2017 | Arsenal | Leicester | 4 | 3 |
| 1 | 12/08/2017 | Brighton | Man City | 0 | 2 |
| 2 | 12/08/2017 | Chelsea | Burnley | 2 | 3 |
| 3 | 12/08/2017 | Crystal Palace | Huddersfield | 0 | 3 |
| 4 | 12/08/2017 | Everton | Stoke | 1 | 0 |
Building the model
The model itself doesn't change from last time. We are still assuming that the number of goals a team scores is a function of their attack strength combined with the opposition's defence strength. In other words, teams with better attacks should score more and teams with worse defences should concede more. We also include home field advantage.
So the model still looks like this:
goals_home = home_advantage + home_attack + defence_away
goals_away = away_attack + defence_home
Finding the Optimal parameters
Now we finally get to the part where things start to change. Dixon and Coles recognised that the Poisson model was struggling with the 0-0, 1-0 and 1-0 score lines and proposed adding in an extra parameter (known as $\rho$ or rho) to the model that provides dependance between these scores. This is done in such a way that ensures the marginal distribution remain Poisson shaped.
def rho_correction(goals_home, goals_away, home_exp, away_exp, rho):
if goals_home == 0 and goals_away == 0:
return 1 - (home_exp * away_exp * rho)
elif goals_home == 0 and goals_away == 1:
return 1 + (home_exp * rho)
elif goals_home == 1 and goals_away == 0:
return 1 + (away_exp * rho)
elif goals_home == 1 and goals_away == 1:
return 1 - rho
else:
return 1.0
Next, we need to tweak our log_likelihood function from the last article to calculate the new rho_correction and add it on to our log-likelihood.
def log_likelihood(
goals_home_observed,
goals_away_observed,
home_attack,
home_defence,
away_attack,
away_defence,
home_advantage,
rho,
):
goal_expectation_home = np.exp(home_attack + away_defence + home_advantage)
goal_expectation_away = np.exp(away_attack + home_defence)
home_llk = poisson.pmf(goals_home_observed, goal_expectation_home)
away_llk = poisson.pmf(goals_away_observed, goal_expectation_away)
adj_llk = rho_correction(
goals_home_observed,
goals_away_observed,
goal_expectation_home,
goal_expectation_away,
rho,
)
if goal_expectation_home < 0 or goal_expectation_away < 0 or adj_llk < 0:
return 10000
log_llk = np.log(home_llk) + np.log(away_llk) + np.log(adj_llk)
return -log_llk
We also need make some minor updates to the code we wrapped around scipy's optimizer to add in rho. Compared with the version from the last article, we've added an extra value to params for rho and updated _fit to pass rho through to the log_likelihood function. We're also printing out res["fun"], which is the value of the log likelihood our optimised set of parameters gives us.
from pprint import pprint
import numpy as np
from scipy.optimize import minimize
from scipy.stats import poisson
def fit_poisson_model():
teams = np.sort(np.unique(np.concatenate([df["HomeTeam"], df["AwayTeam"]])))
n_teams = len(teams)
params = np.concatenate(
(
np.random.uniform(0.5, 1.5, (n_teams)), # attack strength
np.random.uniform(0, -1, (n_teams)), # defence strength
[0.25], # home advantage
[-0.1], # rho
)
)
def _fit(params, df, teams):
attack_params = dict(zip(teams, params[:n_teams]))
defence_params = dict(zip(teams, params[n_teams : (2 * n_teams)]))
home_advantage = params[-2]
rho = params[-1]
llk = list()
for idx, row in df.iterrows():
tmp = log_likelihood(
row["FTHG"],
row["FTAG"],
attack_params[row["HomeTeam"]],
defence_params[row["HomeTeam"]],
attack_params[row["AwayTeam"]],
defence_params[row["AwayTeam"]],
home_advantage,
rho
)
llk.append(tmp)
return np.sum(llk)
options = {
"maxiter": 100,
"disp": False,
}
constraints = [{"type": "eq", "fun": lambda x: sum(x[:n_teams]) - n_teams}]
res = minimize(
_fit,
params,
args=(df, teams),
constraints=constraints,
options=options,
)
model_params = dict(
zip(
["attack_" + team for team in teams]
+ ["defence_" + team for team in teams]
+ ["home_adv", "rho"],
res["x"],
)
)
print("Log Likelihood: ", res["fun"])
return model_params
Let's run the code and see what the model's parameters look like.
model_params = fit_poisson_model()
pprint(model_params)
'Log Likelihood:' 1050.8007455859752
{'attack_Arsenal': 1.4475806767563462,
'attack_Bournemouth': 0.9564134429072025,
'attack_Brighton': 0.6846752119668259,
'attack_Burnley': 0.6983313339318459,
'attack_Chelsea': 1.2572225786245756,
'attack_Crystal Palace': 0.9493623391542453,
'attack_Everton': 0.9377478892934925,
'attack_Huddersfield': 0.48934382402256327,
'attack_Leicester': 1.189901145845123,
'attack_Liverpool': 1.5643592069690049,
'attack_Man City': 1.786002855268045,
'attack_Man United': 1.3309393567717684,
'attack_Newcastle': 0.7670321482410185,
'attack_Southampton': 0.7651647511032018,
'attack_Stoke': 0.7195758814775219,
'attack_Swansea': 0.46645544795474325,
'attack_Tottenham': 1.4273383910058157,
'attack_Watford': 0.9338520316567531,
'attack_West Brom': 0.5837325635190684,
'attack_West Ham': 1.0449689235308348,
'defence_Arsenal': -0.9058108004220589,
'defence_Bournemouth': -0.758464198660216,
'defence_Brighton': -0.8946000243344525,
'defence_Burnley': -1.2266994646301788,
'defence_Chelsea': -1.2203046589466593,
'defence_Crystal Palace': -0.8536543328557012,
'defence_Everton': -0.8097571454511648,
'defence_Huddersfield': -0.8264395373062519,
'defence_Leicester': -0.7548204664366124,
'defence_Liverpool': -1.1755563808950777,
'defence_Man City': -1.515837101040477,
'defence_Man United': -1.5183987188316523,
'defence_Newcastle': -1.0403853901493407,
'defence_Southampton': -0.8498059001250292,
'defence_Stoke': -0.6625948352647537,
'defence_Swansea': -0.865693751408734,
'defence_Tottenham': -1.272001837824072,
'defence_Watford': -0.7091269693877006,
'defence_West Brom': -0.8701857668132795,
'defence_West Ham': -0.6432122607551816,
'home_adv': 0.29444537714494584,
'rho': -0.1285194379447786}
Reassuringly, this look pretty similar to the parameters we got in the last article.
Even better, our log likelihood is 1050.80, which is lower than the 1052.34 we get if we re-run the model from the previous article. This means the new model fits the data better :)
But What Does rho Actually Do?
So how has adding rho into the model managed to improve things?
If you remember all the way back to the last article, I mentioned that one of the issues with our Poisson model was that it predicted each team's goals independently from each other.
In reality though, each team's goals scored are not independent from each other. For example, if the score is 0-0 with five minutes to go then the underdog may settle for a draw and not push to score. Or if a team goes a goal down early on they may park the buss to prevent a more humiliating score line.
Whilst goals are generally Poisson distributed, there are situations where their Poisson-ness breaks down somewhat. Dixon and Cole's adjustment using rho is an attempt to fix this by adding some dependance between the score lines.
As an example, let's look at the difference between the probabilities of of the 0-0, 1-0 and 0-1 scores before and after applying the Dixon and Coles adjustment.
We start off by getting the model's parameters and using them to calculate the number of goals we expect each team to score. Then we use this to get the probability of 0 and 1 goals being scored (the Dixon and Coles adjustment only affects those score lines of 0 and 1 goals so we won't bother going any higher).
We then take the outer product of the two sets of probabilities to create a matrix, apply the Dixon and Coles adjustment and print out how the probabilities changed.
home_team = "Arsenal"
away_team = "Chelsea"
home_attack = model_params["attack_" + home_team]
home_defence = model_params["defence_" + home_team]
away_attack = model_params["attack_" + away_team]
away_defence = model_params["defence_" + away_team]
home_advantage = model_params["home_adv"]
rho = model_params["rho"]
home_goal_expectation = np.exp(home_attack + away_defence + home_advantage)
away_goal_expectation = np.exp(away_attack + home_defence)
home_probs = poisson.pmf([0, 1], home_goal_expectation)
away_probs = poisson.pmf([0, 1], away_goal_expectation)
probability_matrix_before = np.outer(home_probs, away_probs)
probability_matrix_after = probability_matrix_before.copy()
probability_matrix_after[0, 0] *= 1 - home_goal_expectation * away_goal_expectation * rho
probability_matrix_after[0, 1] *= 1 + home_goal_expectation * rho
probability_matrix_after[1, 0] *= 1 + away_goal_expectation * rho
probability_matrix_after[1, 1] *= 1 - rho
print(probability_matrix_after - probability_matrix_before)
array([[ 0.01377996, -0.01377996],
[-0.01377996, 0.01377996]])
The top-left value has increased by 0.01377996, which has been taken from the top-right value. This means the Dixons and Coles adjustment has increased the likelihood of a 0-0 score line occurring at the expense of 1-0.
The opposite has also occurred in the bottom row, where the bottom-right value has increased at the expense of the bottom-left value. This means the probability of a 1-1 score line has increased whilst 0-1 has decreased.
So Dixon and Cole's model increases the probability of low score draws compared with our basic Poisson model. It's not a massive change to the probabilities but it's certainly enough to improve the model's overall performance.
Time Decay
Now that we've sorted out the issue with the dependance between scores, we have a second problem we need to handle.
At the moment we're considering team's attack and defence ratings to be static. But in reality they actually change over time. Think about how Sheffield United finished 9th in 2019/2020 yet were bottom of the league in 2020/2021. If we were to train our model using both season's worth of data then we'd probably end up overrating how many goals we'd expect Sheffield United to have scored in 2020/2021.
We could solve this by only training our model over a short time window to ensure we just use the most recent fixtures for a team. But then we'd be at risk of the model reacting to short term trends in form rather than a team's true ability.
So how do we determine how much data to train the model on?
Dixon and Coles proposed using exponential decay to down-weight the importance of fixtures based on how long it is since they were played. This means the model can be trained on lots of historical data, with it placing more importance on the most recent fixtures but without completely losing the influence of older fixtures.
Here's the function they suggested:
$$\phi(t) = exp(-\xi t)$$
And here's its implementation in python, where xi controls the strength of the down-weighting and t is the time since the fixture was played.
def dc_decay(xi, t):
return np.exp(-xi * t)
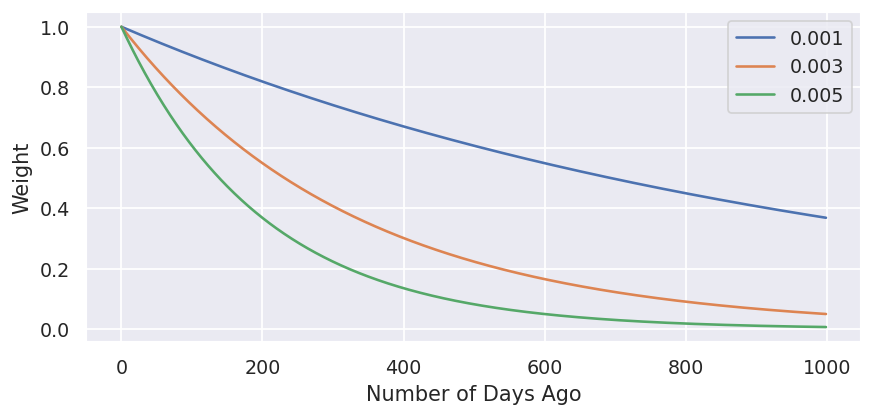
Lets plot out a few different values of xi to see what the down-weighting looks like, where the lower the weight the less important the fixture becomes.
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
t = np.array(range(1000))
xis = [0.001, 0.003, 0.005]
for xi in xis:
plt.plot(t, dc_decay(xi, t), label=str(xi))
plt.legend()
plt.xlabel("Number of Days Ago")
plt.ylabel("Weight")
Optimising the Time decay
So the larger the value of xi then the more extreme the down-weighting is. But what value should xi be?
Ideally, you would optimize your model in a similar way to how we found our attack / defence parameters above and work out the exact value of xi that gives you the best performance. To keep the code a little simpler here though, we're just going to loop through a few different values to see the effect of tweaking xi.
Whilst we're still using log likelihood to optimise the model itself, we're going to need to use a different metric to compare the values of xi to find out which one is best. We'll do this using Rank Probability Scores.
Ranked Probability Scores were original proposed by Epstein back in 1969 as a way to compare probabilistic forecasts against categorical data. Their main advantage here is that as well as looking at accuracy, they also account for distance in the predictions e.g. how far out inaccurate predictions are from what actually happened. This means we can measure the accuracy of our win / draw / loss probabilities against each match's outcome and measure the overall error.
To keep things simple, we'll download the penaltyblog python package and use the rps function from there - the idea of this article is to focus on the Dixon and Coles model itself rather than get sidetracked with implementing different metrics.
Install the penaltyblog package by running the command below in your terminal.
pip install penaltyblog
We'll then use the penaltyblog package to download more data from football-data.co.uk, giving us five season's worth of fixtures to play with.
import penaltyblog as pb
import pandas as pd
df = pd.concat([
pb.footballdata.fetch_data("england", 2016, 0),
pb.footballdata.fetch_data("england", 2017, 0),
pb.footballdata.fetch_data("england", 2018, 0),
pb.footballdata.fetch_data("england", 2019, 0),
pb.footballdata.fetch_data("england", 2020, 0),
])
The next thing we need to do is to update our log_likelihood function to apply the weighting. It's a fairly simple change here, all we do is pass in the weight for the fixture as an additional argument and then multiply the log likelihood by the weight.
def log_likelihood(
goals_home_observed,
goals_away_observed,
home_attack,
home_defence,
away_attack,
away_defence,
home_advantage,
rho,
weight
):
goal_expectation_home = np.exp(home_attack + away_defence + home_advantage)
goal_expectation_away = np.exp(away_attack + home_defence)
home_llk = poisson.pmf(goals_home_observed, goal_expectation_home)
away_llk = poisson.pmf(goals_away_observed, goal_expectation_away)
adj_llk = rho_correction(
goals_home_observed,
goals_away_observed,
goal_expectation_home,
goal_expectation_away,
rho,
)
if goal_expectation_home < 0 or goal_expectation_away < 0 or adj_llk < 0:
return 10000
log_llk = weight * (np.log(home_llk) + np.log(away_llk) + np.log(adj_llk))
return -log_llk
Now we need to update the code that wraps the call to the optimizer. The main change here is that we pass in our value for xi and create weights for the fixtures based on how long ago they were played.
def fit_poisson_model(df, xi=0.0001):
teams = np.sort(np.unique(np.concatenate([df["HomeTeam"], df["AwayTeam"]])))
n_teams = len(teams)
df["days_since"] = (df["Date"].max() - df["Date"]).dt.days
df["weight"] = dc_decay(xi, df["days_since"])
params = np.concatenate(
(
np.random.uniform(0.5, 1.5, (n_teams)), # attack strength
np.random.uniform(0, -1, (n_teams)), # defence strength
[0.25], # home advantage
[-0.1], # rho
)
)
def _fit(params, df, teams):
attack_params = dict(zip(teams, params[:n_teams]))
defence_params = dict(zip(teams, params[n_teams : (2 * n_teams)]))
home_advantage = params[-2]
rho = params[-1]
llk = list()
for idx, row in df.iterrows():
tmp = log_likelihood(
row["FTHG"],
row["FTAG"],
attack_params[row["HomeTeam"]],
defence_params[row["HomeTeam"]],
attack_params[row["AwayTeam"]],
defence_params[row["AwayTeam"]],
home_advantage,
rho,
row["weight"],
)
llk.append(tmp)
return np.sum(llk)
options = {
"maxiter": 100,
"disp": False,
}
constraints = [{"type": "eq", "fun": lambda x: sum(x[:n_teams]) - n_teams}]
res = minimize(
_fit,
params,
args=(df, teams),
constraints=constraints,
options=options,
)
model_params = dict(
zip(
["attack_" + team for team in teams]
+ ["defence_" + team for team in teams]
+ ["home_adv", "rho"],
res["x"],
)
)
return model_params
Once we've fit our model, we'll use it to calculate the probabilities of a win / draw / loss occurring for each fixture and then measure the rank probability score of our predictions compared with what actually happened.
We will also split the data up so that we train on the first fours seasons and predict on the final season. This means our model is predicting on different data to that it was trained on to help avoid overfitting.
Here's the updated predict function that returns home win, draw, away win probabilities.
def predict(params, home_team, away_team):
home_attack = params["attack_" + home_team]
home_defence = params["defence_" + home_team]
away_attack = params["attack_" + away_team]
away_defence = params["defence_" + away_team]
home_advantage = params["home_adv"]
rho = params["rho"]
home_goal_expectation = np.exp(home_attack + away_defence + home_advantage)
away_goal_expectation = np.exp(away_attack + home_defence)
home_probs = poisson.pmf(range(10), home_goal_expectation)
away_probs = poisson.pmf(range(10), away_goal_expectation)
m = np.outer(home_probs, away_probs)
m[0, 0] *= 1 - home_goal_expectation * away_goal_expectation * rho
m[0, 1] *= 1 + home_goal_expectation * rho
m[1, 0] *= 1 + away_goal_expectation * rho
m[1, 1] *= 1 - rho
home = np.sum(np.tril(m, -1))
draw = np.sum(np.diag(m))
away = np.sum(np.triu(m, 1))
return home, draw, away
And finally, here's the function that calculates the ranked probability score from those probabilities.
def calculate_rps(params, df):
rps = list()
for idx, row in df.iterrows():
if row["FTR"] == "H":
outcome = 0
elif row["FTR"] == "D":
outcome = 1
elif row["FTR"] == "A":
outcome = 2
predictions = predict(params, row["HomeTeam"], row["AwayTeam"])
rps.append(pb.metrics.rps(predictions, outcome))
return np.mean(rps)
All we have to do now is loop through some values for xi and see what happens. Warning - you may want to go and make a coffee at this point as it's going to take a while to loop through all this. At the moment the code is very much written for simplicity rather than speed but I'll show you a faster way to do this bit later on via the penaltyblog python package.
xis = [0, 0.00005, 0.0001, 0.001, 0.0025,]
rps = list()
for xi in xis:
train = df.iloc[-380:]
test = df.iloc[-380:]
train["days_since"] = (train["Date"].max() - train["Date"]).dt.days
train["weight"] = dc_decay(xi, train["days_since"])
params = fit_poisson_model(train, xi)
rps.append(calculate_rps(params, test))
plt.plot(xis, rps)
plt.ticklabel_format(useOffset=False)
plt.xlabel("xi")
plt.ylabel("RPS")
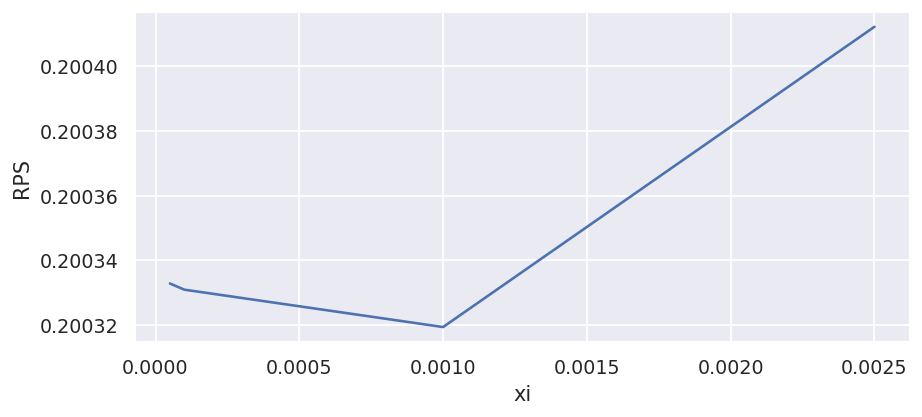
Rank probability scores are a measure of the error in our predictions so the smaller the value the better the model is performing. It looks like we are doing best with an xi of roughly 0.001. Smaller xi values are likely providing too much influence to the older data, whilst larger xi values are giving too much influence to the latest data.
In Dixon and Cole's paper, the authors report using an xi value of 0.0065. However, their time units are half weeks whilst ours are in days. If we divide 0.0065 by 3.5 (the number of days in a half week) then we get 0.00186, which is in line with our value of 0.001.
Conclusions
This has been a long article with a lot of code so thanks for reading it all the way to the end!
With relatively minor modifications, we've upgraded our Poisson model to use the Dixon and Coles adjustment to improve its predictions for the 0-0, 0-1 and 1-0 score lines.
We've also added in time decay so that we down-weight the influence of older data when we fit the model and give greater influence to more recent fixtures.
This isn't the end of the road though. There's plenty of other things we can do to improve our model, which I'll cover in future articles.
Addendum
I mentioned above that the function we were using to optimize was slow as the code was written for simplicity rather than speed. I've neatened up the code and added it my penaltyblog python package if you want to try out a faster version.
Using penaltyblog we can repeat everything we've done above in just a few lines of code and and have it run in minutes rather than hours.
pip install penaltyblog
import penaltyblog as pb
import pandas as pd
import numpy as np
def calculate_mean_rps(dc, df):
rps = list()
for idx, row in df.iterrows():
if row["FTR"] == "H":
outcome = 0
elif row["FTR"] == "D":
outcome = 1
elif row["FTR"] == "A":
outcome = 2
predictions = dc.predict(row["HomeTeam"], row["AwayTeam"]).home_draw_away
rps.append(pb.metrics.rps(predictions, outcome))
return np.mean(rps)
df = pd.concat([
pb.footballdata.fetch_data("england", 2016, 0),
pb.footballdata.fetch_data("england", 2017, 0),
pb.footballdata.fetch_data("england", 2018, 0),
pb.footballdata.fetch_data("england", 2019, 0),
pb.footballdata.fetch_data("england", 2020, 0),
]).reset_index()
rps = list()
for xi in [0, 0.0001, 0.001, 0.02,]:
train = df.iloc[:-300]
test = df.iloc[-300:]
train["weight"] = pb.poisson.dixon_coles_weights(train["Date"], xi)
dc = pb.poisson.DixonColesGoalModel(
train["FTHG"],
train["FTAG"],
train["HomeTeam"],
train["AwayTeam"],
train["weight"],
)
dc.fit()
rps.append(calculate_mean_rps(dc, test))
print(rps)
[0.2214667529243473, 0.22109214369155702, 0.21811162166084946, 0.22953214528180002]