Introduction
Expected goals are one of the hot topics in the football analytics community at the moment and it’s a topic I’ve previously written a number of articles discussing how to calculate them. If you haven’t read those pieces yet it’s probably worth taking a quick look to set the context for the rest of this article.
The Story So Far
A few week’s back I published a simple equation for calculating expected goals that received a lot of positive feedback from readers as it was easy to use and was pretty accurate based on its r squared value of 0.86. This effectively means the equation is capable of explaining 86% of the variance in the shots data I have collected from Squawka.
For such a basic equation this is a really good result. I’d purposely tried to keep things simple so that the equation was easy enough for non-mathematicians to use in order to try and encourage its adoption by other people. Rather than keep these sort of things to myself I’d much rather share them around and see them get used elsewhere.
One of the restrictions I’d set myself for this was to only use the distance the player shooting was from the goal along the X axis so that the equation only needed data along one dimension. However, I received a lot of messages through Twitter and on the blog asking about the Y axis so let’s take a look…
The Y Axis
So the first question to ask was whether the Y axis was even worth bothering with, after all the r squared value when just using distance along the X axis was already 0.86 which only left around 14% of the variance in the data to account for.
Well, it turns out that how far away you are from the goal along the Y axis does have an impact (Figure 1). Unsurprisingly the further away you are then the less likely you are to score. Before you ask, the r squared value is 0.88 (I have learnt now to include r squared values for pretty much all charts otherwise I get bombarded by requests for them :-)).
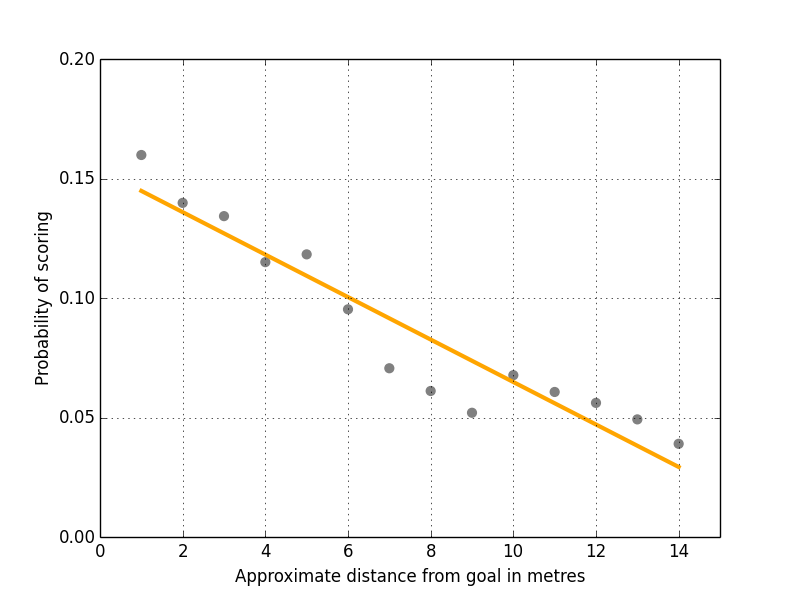
Figure 1: Shots Versus Distance From Goal Along Y Axis
Adding The Y Axis Into The Equation
Okay, we know the Y axis has an effect on expected goals but how do we factor this into my previous equation? There are a number of mathematical techniques we can use to solve for multiple dimensions. However, I am keen to try and make this as simple as possible so that the lay-person can use it so let’s keep it basic and go with Pythagoras’ Theorem, a topic most people have touched on at High School at some point.
If we know the xy coordinates of the player taking the shot and the xy coordinates of the goal then using Pythagoras’ Theorem we can calculate the total distance between the two points. Figure two shows the equation for this where dx is the distance between the two x coordinates, dy is the distance between the two y coordinates and AB is the total distance the player is from the goal.
$AB=sqrt(dx^2+dy^2)$
Figure 2: Calculating the distance between two points
I did this for all 17,000 shots I have collected so far from Squawka (excluding penalties) to get their total distances from goal and calculated the probability of scoring from different distances based on the number of shots taken versus goals scored (Figure 3).
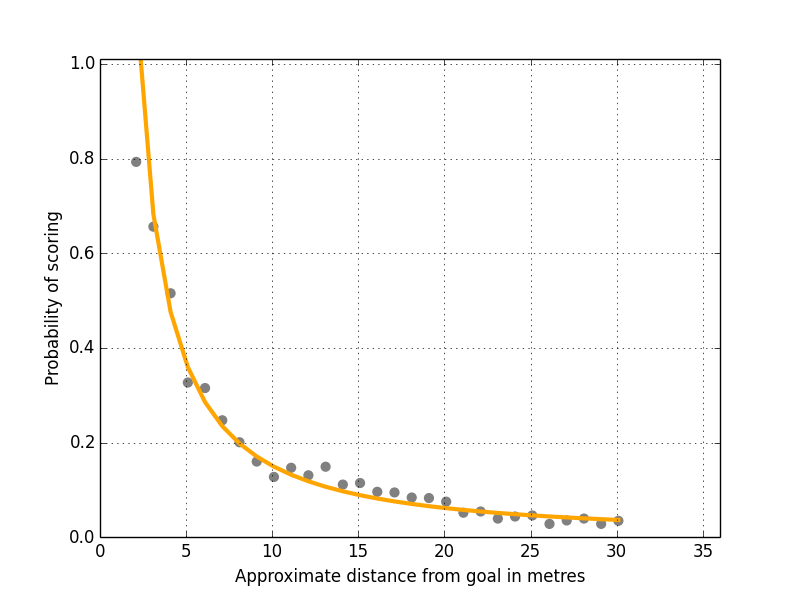
Figure 3: Shots Versus Total Distance From Goal
As previous, I’m using a power curve to fit the line through the data and as you can see it’s a pretty good fit. So what is the effect of adding in the Y axis? Well the r squared value has changed from 0.86 to…
drumroll
0.95
Yep, including both the x and y axis into the expected goals model accounts for 95% of the variance in the data. This barely leaves any room for the shooting player’s talent to have any effect or even for defensive pressure to play a part.
At first I thought this seemed a bit odd but thinking about it in more detail it actually seems logical. It doesn’t make much difference whether you are shooting from five metres out against a strong defence or a weak one, you still have the same chance of scoring from that particular position.
However, playing against a strong defence will likely mean you will get into that good position less often so your overall expected goals will be lower. Conversely, better players will be able to get into those good positions more often than weaker players so their overall expected goals will be higher.
In other words, at the individual shot level expected goals seems to be all about a player’s position in respect to the goal when they shoot. Other factors, such as player talent, defensive pressure etc are probably not visible until you start looking at larger samples, such as expected goals per fixture or even per season.
Anyway, here’s the final equation:
$ExpG=Distance^{-1.33796}*10^{0.4720605}$
Let me know what you think!