Introduction
As there were a couple of presentations at the recent Opta Pro Forum talking about identifying player similarities I thought I’d give a quick example of how to do something similar using k-means cluster analysis.
The Data
All the data used in the analysis was taken from public websites, such as whoscored, squawka, transfermarkt etc and painstakingly matched together to try and get as much information on each player as possible.
The first stage of analysis was to normalize the data so it was all in the same range to avoid biasing the clustering. If you think about how many goals a typical player scores per match compared with how many passes they play then the scale is quite different. Since k-means clustering uses Euclidean Distance the clusters formed are influenced strongly by the magnitudes of the variables, especially by outliers. By normalizing all data into the same range this bias can be avoided.
Principal Component Analysis
While normalizing the data, I also performed Principal Component Analysis (PCA) on it too. This step isn’t essential but it is a handy way of reducing the dimensions in the data down to a more manageable size by squashing all the data together into new variables known as principal components.
These principal components are created in such as way so that the first one accounts for as much as the variance in the data as possible, the second one then accounts for as much of the remaining variance and so on.
As you can see in Figure 1 below, the first component represents pretty much 70% of all the variance in the data with each additional component accounting for less and less. This means we can represent pretty much all the information in the data without losing much using just five components, and around about 80% using just two components.
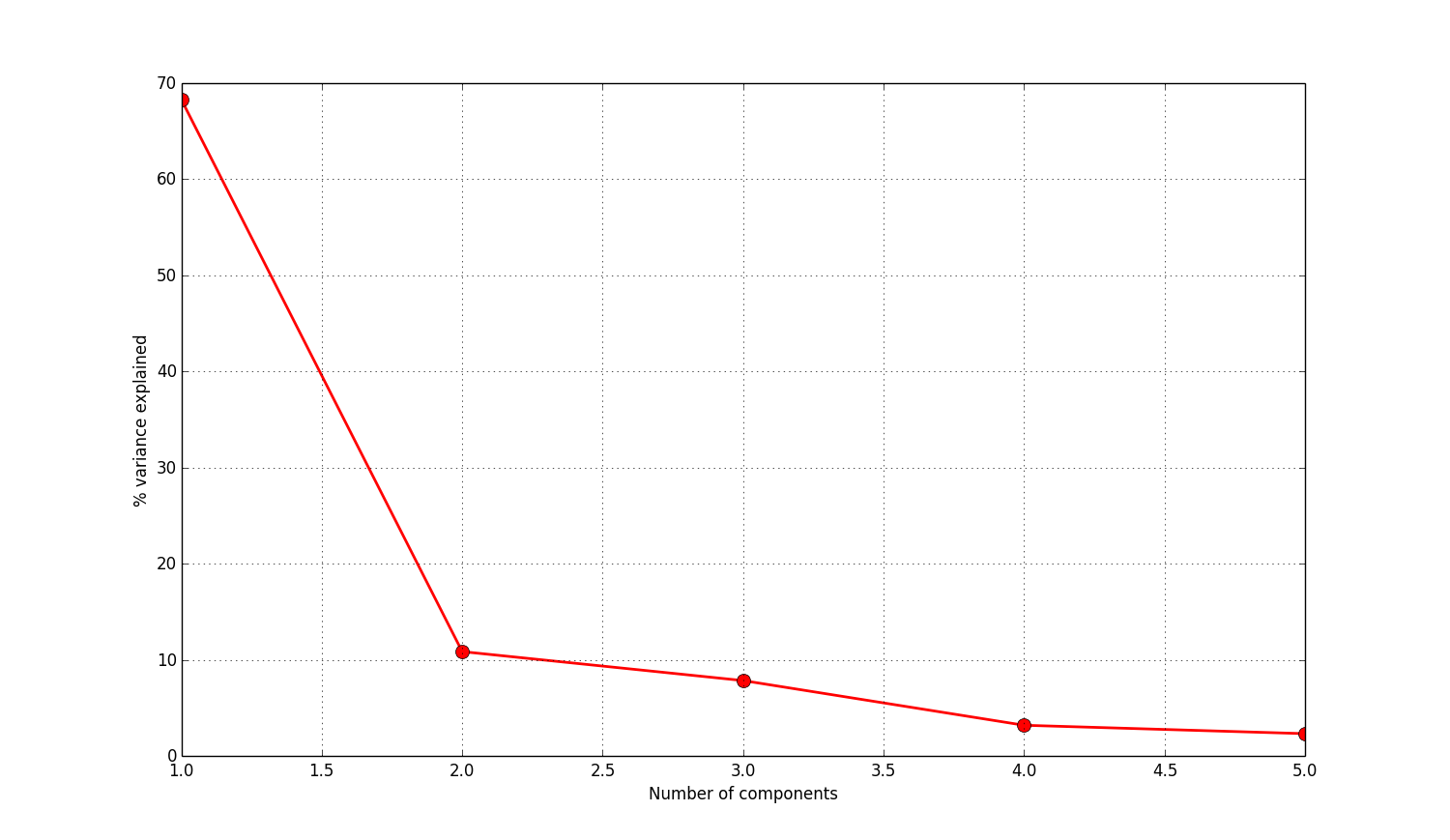
Figure 1: PCA scree plot showing amount of variance accounted for by each principal component
Clustering The Players
The next step was to then run the k-means clustering algorithm on the data. As shown in Figure 2 the players split relatively neatly into five distinct coloured clusters when plotted by the first two principal components.
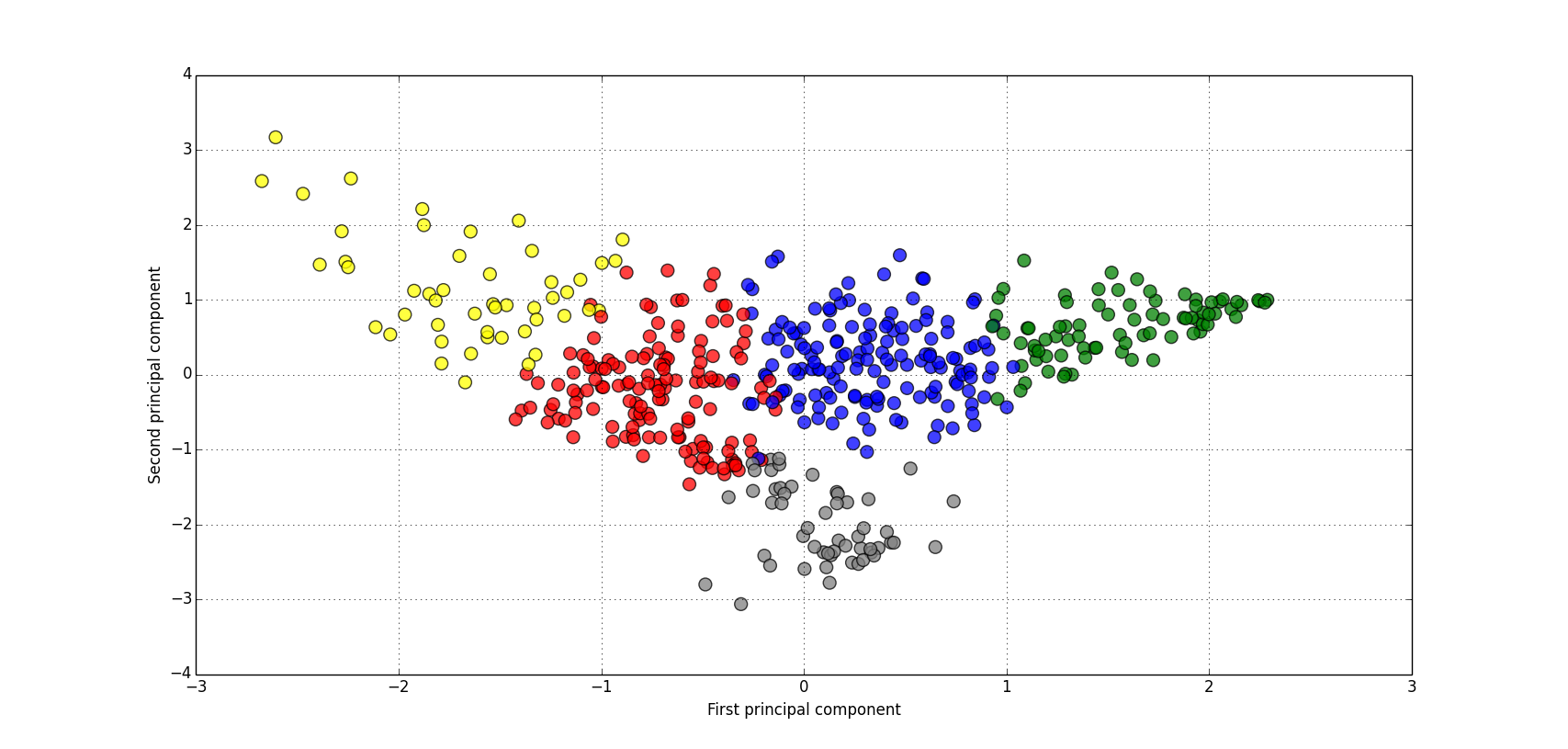
Figure 2: Players split into different clusters by colour
Goalkeepers
As a quick test we can look at the grey cluster located at the bottom of the image in more detail to see which players are contained within it (Figure 3). If you click the image to zoom in on it you can see it’s done a pretty good job of pulling out the goalkeepers from the rest of the players. This is to be expected since goalkeeper’s stats should be pretty distinct from outfield players but it’s reassuring to check the technique passes this first simple test before we move on.
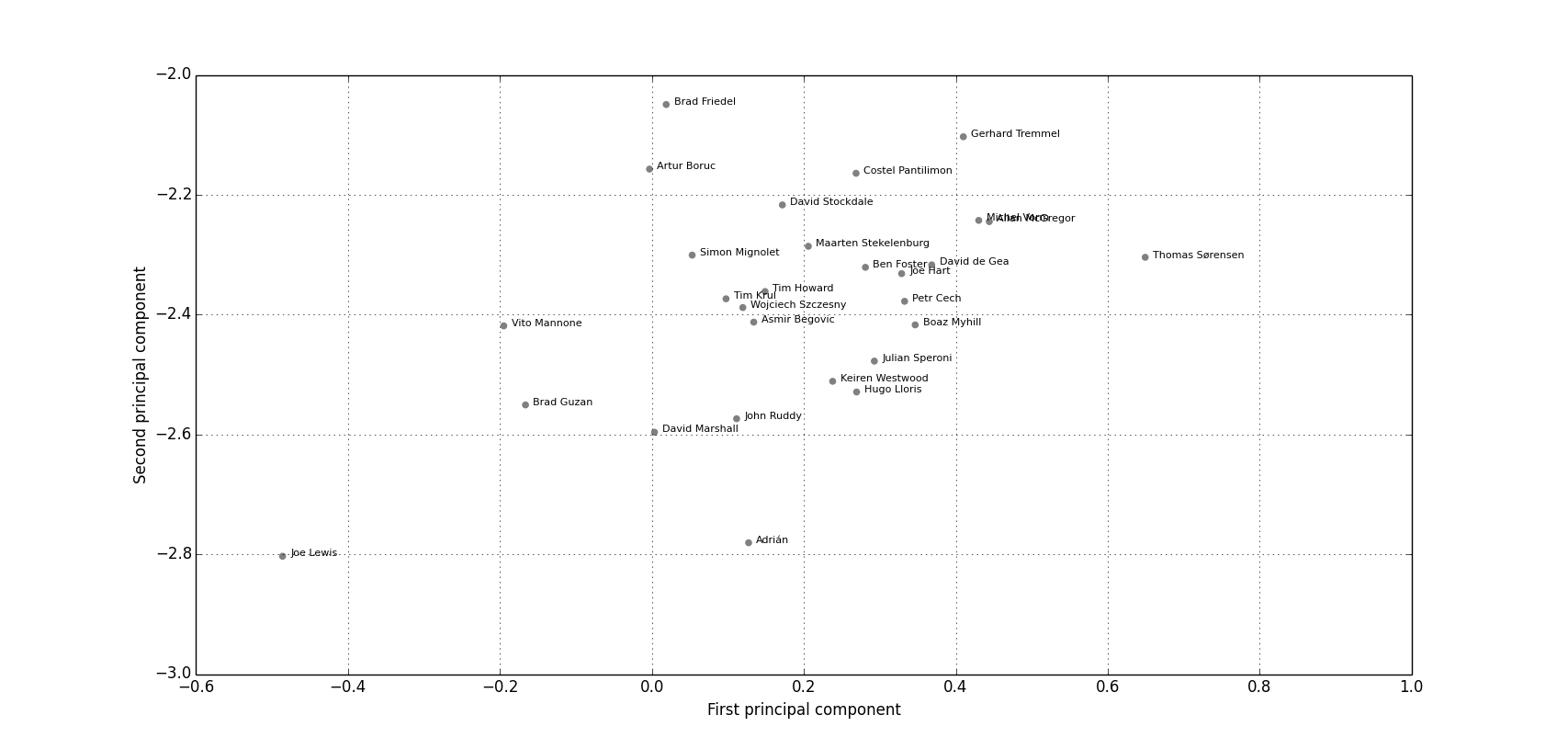
Figure 3: The grey cluster up close
Vincent Kompany
Now that we have separated out the goalkeepers we can take a look at how well the technique copes with outfield players, starting with Manchester City’s central defender Vincent Kompany located at the centre of Figure 4. The results are pretty good, with Kompany surrounded by players predominantly considered to be defenders. As you move up the image the players start to get a bit more attacking with people like David Luiz, Phil Jones and Fabien Delph starting to appear
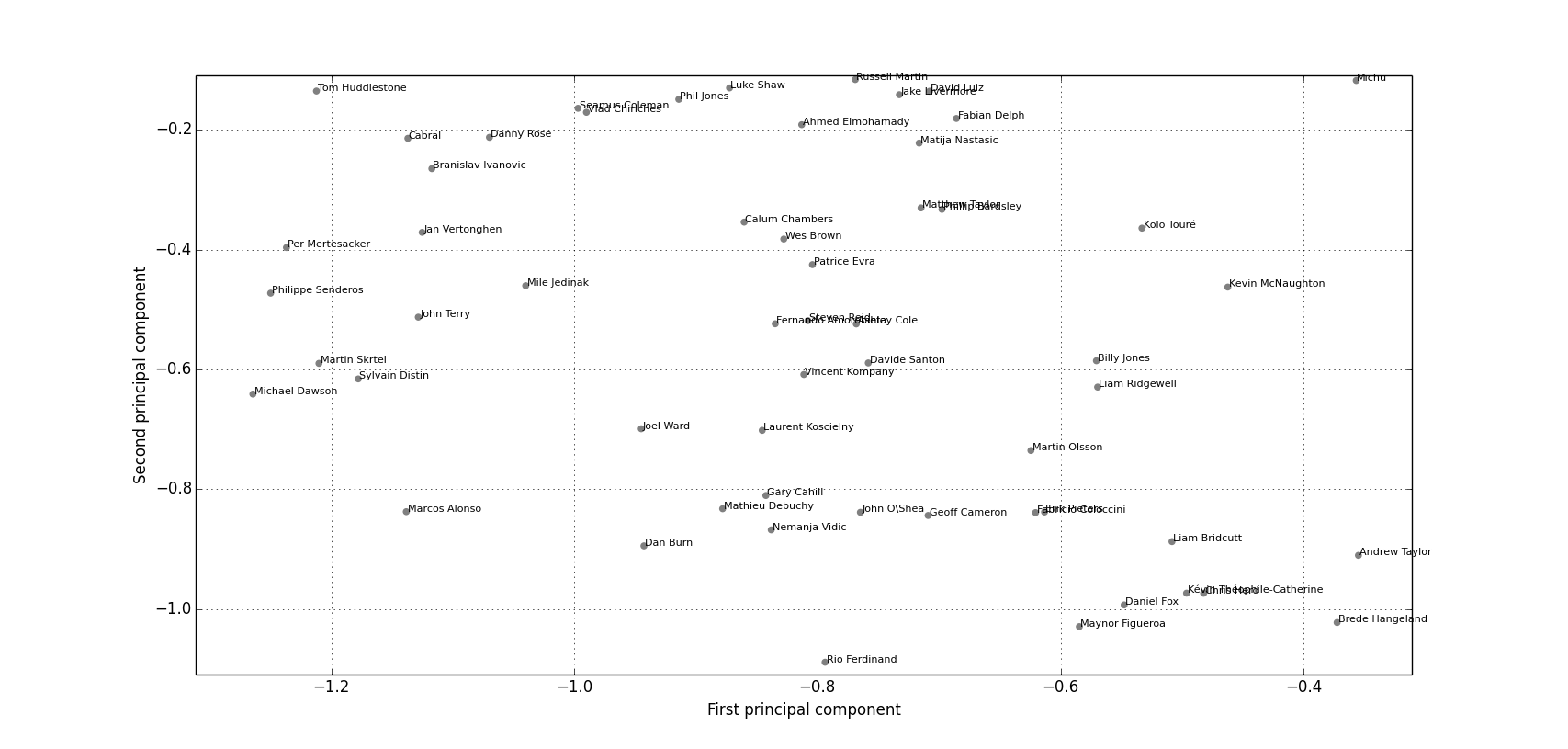
Figure 4: Clustering of Vincent Kompany
Adnan Januzaj
Next up is Adnan Januzaj, one of the few Manchester United players to be having anything resembling a decent season this year. Again the results look pretty plausible (Figure 5), with Januzaj surrounded by predominatly attacking midfielders. There are a couple of slightly surprising results in there though, such as Manchester City’s strikers Álvaro Negredo and Edin Džeko.
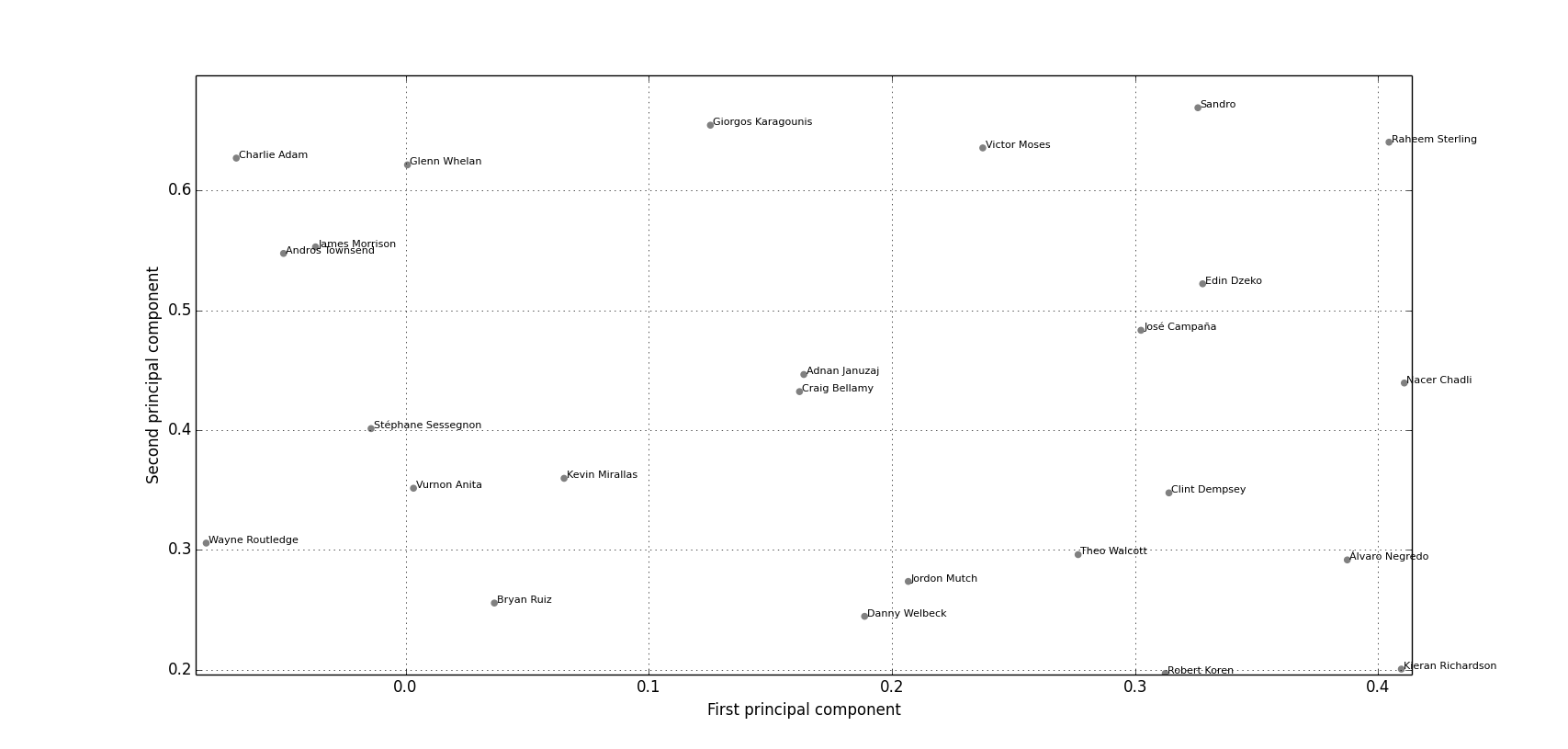
Figure 5: Clustering of Adnan Januzaj
Mikel Arteta
Finally, I added in Arsenal’s midfielder Mikel Arteta (Figure 6). This one was probably the most surprising of all the players I’ve looked at as there seems to be quite a mix of players around Arteta, including both offensive and defensive players, although perhaps this is actually representative of Arteta’s role at Arsenal?
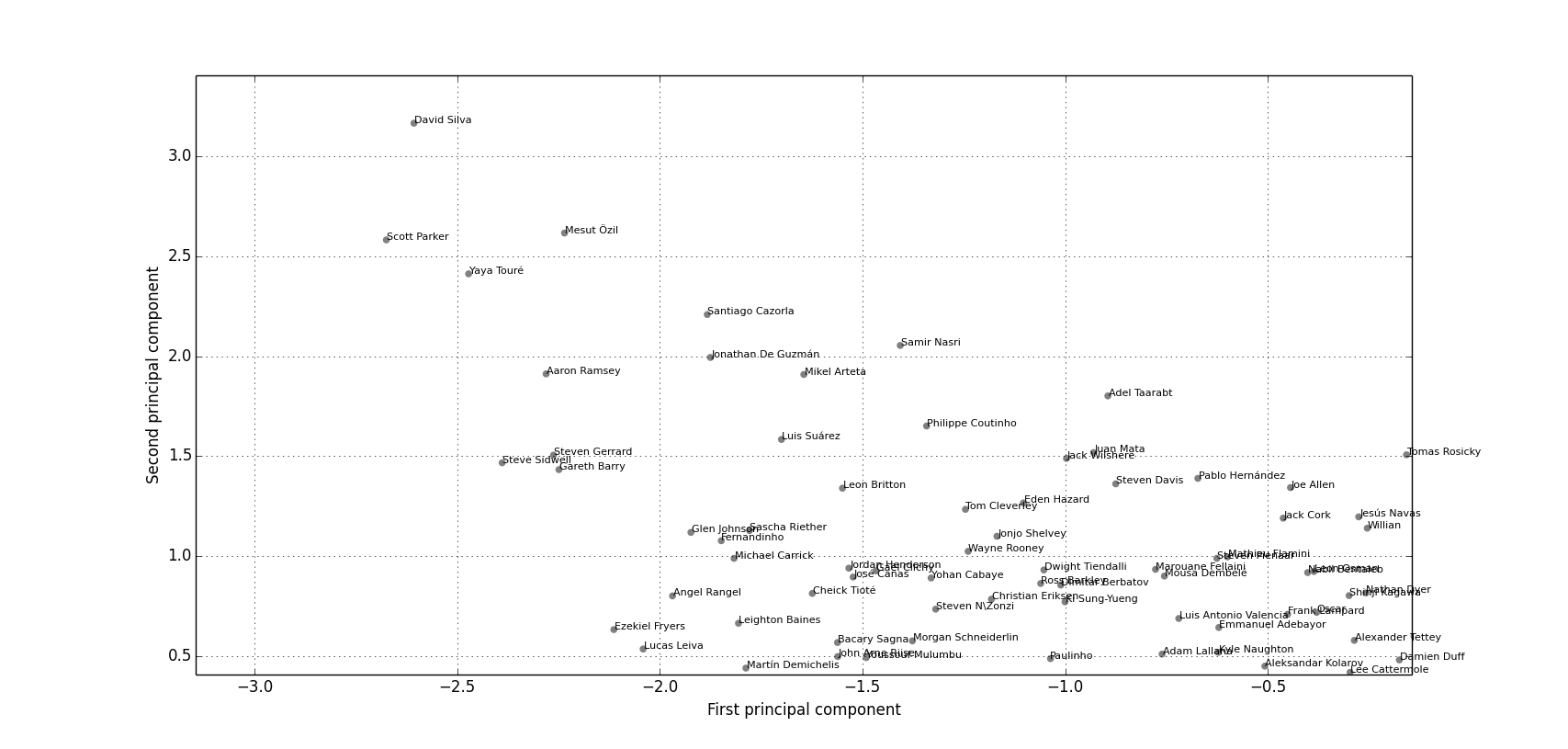
Figure 6: Clustering Mikel Arteta
Next Steps
For a first go the results are pretty promising but there are plenty of ways the technique could be improved. At the moment I have used all the data I had available for each player but I suspect more specific results could be obtained by filtering the data.
For example, there may be specific attributes of a player you want to match on e.g. looking for attackers by just their creative output may be more useful than including their tackles, interceptions etc, which may be of minor importance to their role.
Finally, all the data used here are aggregated. A really interesting next step would be to include xy co-ordinates for shot locations, interceptions, passes etc to cluster players based on the locations of their actions on the pitch (donations of xy data will be gratefully accepted :)).